
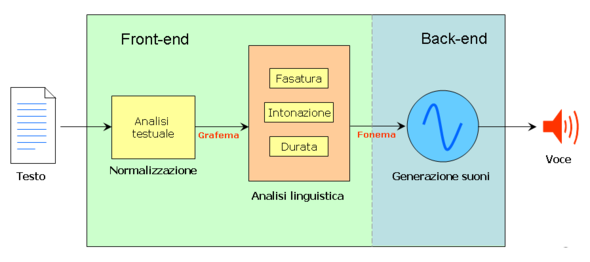
Amazon continua ad innovare nel settore della tecnologia con il lancio di un nuovo modello di sintesi vocale Text-to-Speech (TTS). Questa nuova versione offre miglioramenti significativi rispetto ai modelli precedenti, rendendo l’esperienza dell’ascolto ancora più realistica e coinvolgente.
Grazie a questa nuova tecnologia, gli utenti potranno godere di una voce più naturale e fluida durante la lettura dei testi scritti. Il sistema è in grado di riconoscere e interpretare meglio le intonazioni del linguaggio umano, garantendo una maggiore precisione nella pronuncia delle parole e una migliore comprensione del contesto.
Uno degli elementi chiave che contraddistingue questo nuovo modello è la capacità di adattarsi alle preferenze individuali degli utenti. Attraverso l’utilizzo di algoritmi avanzati di machine learning, Amazon è riuscita a creare un sistema altamente personalizzabile che tiene conto delle caratteristiche vocali specifiche di ciascun individuo.
Inoltre, il nuovo Text-to-Speech di Amazon integra funzionalità aggiuntive per arricchire ulteriormente l’esperienza d’uso. Tra queste troviamo la possibilità di regolare la velocità della lettura, modificare l’accento della voce e selezionare tra diverse opzioni linguistiche disponibili.
L’impatto positivo che questa innovazione potrebbe avere sull’accessibilità digitale non può essere sottovalutato. Grazie alla miglioria della qualità audio e all’aumentata personalizzazione offerta dal nuovo modello TTS, soggetti con disabilità visive o motorie potranno beneficiare appieno dei contenuti digitali senza incontrare barriere comunicative.
In conclusione, il nuovo modello Text-to-Speech introdotto da Amazon rappresenta un passo avanti significativo nel campo della sintesi vocale. La combinazione tra qualità audio superiore, personalizzazione avanzata e funzionalità extra lo rendono uno strumento versatile ed efficace per tutte le esigenze legate alla fruizione del testo scritto attraverso l’ascolto vocale.



Lascia un commento